我们知道,优矿有400+因子库。随着因子库的不断增加,因子库内部有很多因子的信息是会有重复的,或者新检验的有效的因子与因子库里的因子也存在一定的相关性。并且因子也不是越多就越好。本文先研究东方的Alpha因子库精简与优化——《因子选股系列研究之十》是怎么做的。东方证券:Alpha因子库精简与优化——《因子选股系列研究之十》
importnumpyasnpimportpandasaspdfromdatetimeimportdatetime,__style('white')*拿取上海证券交易所日历cal_dates=(exchangeCD=u"XSHG",beginDate=begin,Date=)cal_dates=cal_dates[cal_dates['isOpen']==1].sort('calarDate')按天拿取因子数据,并保存为一个dataframedf=()fordtincal_dates:打印进度部分,每200天打印一次ifcount0andcount%200==0:finish_time=()printcount,print''+str(((finish_time-start_time)-secs_time,0))+'secondselapsed.'secs_time=(finish_time-start_time)count+=1将上市不满三个月的股票的因子设置为NaNequ_info=(equTypeCD=u"A",secID=u"",ticker=u"",listStatusCD=u"",field=u"",pandas="1")equ_info=equ_info[['secID','listDate','delistDate']].set_index('secID')equ_info['delistDate']=[xiftype(x)==strelseforxinequ_info['delistDate']]equ_info['listDate']=_datetime(equ_info['listDate'],format='%Y-%m-%d')equ_info['delistDate']=_datetime(equ_info['delistDate'],format='%Y-%m-%d')equ_info['listDate']=[x+timedelta(90)forxinequ_info['listDate']]:sec_info=equ_[sec][:sec_info['listDate'],sec]=[sec_info['delistDate']:,sec]=可见的数据:2016-12-27这日的因子数据,只能由2016-12-26这天和这天之前的相df=(1).stack()returndf
defgetUqerPrices(begin,,universe,price='openPrice'):"""使用优矿的行情DataAPI,拿取所需的行情数据,并整理成相应格式,返回的数据格式为pandasDataFrame,例如::str开始日期,'YYYY-mm-dd'或'YYYYmmdd':str截止日期,'YYYY-mm-dd'或'YYYYmmdd'universe:list股票池,格式为uqer股票代码secIDfactor:str行情对应名称,uqer的行情api可以获取的行情名称Returns-------df:行情数据,index为tradeDate,columns为secID."""每段长度trade_cal=(exchangeCD=u"XSHG",beginDate=begin,Date=)trade_cal=trade_cal[trade_cal['isOpen']==1].sort('calarDate')cal_tmp=trade_[::step]分段读取数据,并进行拼接df=()forx,yindates_tup:dt_df=(beginDate=x,Date=y,secID=universe,field=['tradeDate','secID']+[price]):df=dt_dfelse:df=(dt_df)提取所需的universe对应的价格数据df=_index(['tradeDate','secID'])[price].unstack()universe=list(set(universe)set())=_datetime(,format='%Y-%m-%d')returndf[universe]
defmonth_ic(factor_data,forward_return_data):计算相关系数fordtinic_:ifdtnotinforward_return_:continuetmp_factor=factor_[dt]tmp_ret=forward_return_[dt]fct=(tmp_factor)ret=(tmp_ret)=['fct']=['ret']fct['ret']=ret['ret']fct=fct[~(fct['fct'])][~(fct['ret'])]iflen(fct)20:continueic,p_value=(fct['fct'],fct['ret'])预处理returns_3m=RETURNS_3[3:]returns_1m=RETURNS_1[returns_3,:]illiquidity=[returns_3,:]vol20=[returns_3,:]bp=[returns_3,:]
Fama-MacbethRegressionlambda_=[]fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index))x=zip((returns_3[date,sec_list]))y=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)lambda_.app(_[0])
假设检验:
print'p-value:',_1samp(lambda_,0)[1]
p-value:0.00616015864039
p值小于0,所以拒绝原假设,也就是说3个月反转收益因子首先可以加入因子库。这里我们第一次循环就做完了。
**step1:**将BP,RETURNS_1m,ILLIQUIDITY,VOL20,IVR,分别与RETURNS_3m进行回归并得到残差。
theta1=(index=returns_3,columns=returns_3)fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set(returns_1[date,:].dropna().index))x=zip((returns_3[date,sec_list]))y=(returns_1[date,sec_list])iflen(x)0andlen(y)0:linreg=LinearRegression(fit_intercept=True)model=(x,y)y_pred=(x)[date,sec_list]=y-y_predtheta2=(index=returns_3,columns=returns_3)fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set([date,:].dropna().index))x=zip((returns_3[date,sec_list]))y=([date,sec_list])iflen(x)0andlen(y)0:linreg=LinearRegression(fit_intercept=True)model=(x,y)y_pred=(x)[date,sec_list]=y-y_predtheta3=(index=returns_3,columns=returns_3)fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set([date,:].dropna().index))x=zip((returns_3[date,sec_list]))y=([date,sec_list])iflen(x)0andlen(y)0:linreg=LinearRegression(fit_intercept=True)model=(x,y)y_pred=(x)[date,sec_list]=y-y_predtheta4=(index=returns_3,columns=returns_3)fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set([date,:].dropna().index))x=zip((returns_3[date,sec_list]))y=([date,sec_list])iflen(x)0andlen(y)0:linreg=LinearRegression(fit_intercept=True)model=(x,y)y_pred=(x)[date,sec_list]=y-y_predtheta5=(index=,columns=):sec_list=list(set(returns_3[date,:].dropna().index)set([date,:].dropna().index))x=zip((returns_3[date,sec_list]))y=([date,sec_list])iflen(x)0andlen(y)0:linreg=LinearRegression(fit_intercept=True)model=(x,y)y_pred=(x)[date,sec_list]=y-y_pred
**step2:**将残差和3个月反转收益因子一起做个Fama-Macbeth回归,记录因子的系数,以及调整的R2
lambd1=[]r_2_1=[]fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index)set([date,:].dropna().index))iflen(sec_list)0:x=([list(returns_3[date,sec_list]),list([date,sec_list])]).Ty=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)(_[1])r_2_1.app((x,y))lambd2=[]r_2_2=[]fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index)set([date,:].dropna().index))iflen(sec_list)0:x=([list(returns_3[date,sec_list]),list([date,sec_list])]).Ty=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)(_[1])r_2_2.app((x,y))lambd3=[]r_2_3=[]fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index)set([date,:].dropna().index))iflen(sec_list)0:x=([list(returns_3[date,sec_list]),list([date,sec_list])]).Ty=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)(_[1])r_2_3.app((x,y))lambd4=[]r_2_4=[]fordateinreturns_3:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index)set([date,:].dropna().index))iflen(sec_list)0:x=([list(returns_3[date,sec_list]),list([date,sec_list])]).Ty=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)(_[1])r_2_4.app((x,y))lambd5=[]r_2_5=[]:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index)set([date,:].dropna().index))iflen(sec_list)0:x=([list(returns_3[date,sec_list]),list([date,sec_list])]).Ty=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)(_[1])r_2_5.app((x,y))
step3,step4:再来看看系数的显著性,剔除那些不显著的因子,选择显著性检验通过并且横截面回归R2平均值最大的因子。
printu'1个月反转收益因子','p-value:',_1samp(lambd1,0)[1],';','可决系数均值:',(r_2_1)printu'非流动性因子','p-value:',_1samp(lambd2,0)[1],';','可决系数均值:',(r_2_2)printu'20日换手率因子','p-value:',_1samp(lambd3,0)[1],';','可决系数均值:',(r_2_3)printu'BP因子','p-value:',_1samp(lambd4,0)[1],';','可决系数均值:',(r_2_4)printu'IVR因子','p-value:',_1samp(lambd5,0)[1],';','可决系数均值:',(r_2_5)
1个月反转收益因子p-value:0.941194888256;可决系数均值:0.0311845405958非流动性因子p-value:6.49532628633e-05;可决系数均值:0.03372751469620日换手率因子p-value:0.948573256553;可决系数均值:0.02703786586BP因子p-value:0.92448984796;可决系数均值:0.0388933569553IVR因子p-value:3.e-10;可决系数均值:0.0253165524167
这样我们第一步应该保留非流动性因子,而1个月反转收益因子,20日换手率因子,BP因子因为系数不显著,予以剔除。
现在应该进入第三次筛选,考察是否加入特异度因子。
theta=(index=,columns=):sec_list=list(set(returns_3[date,:].dropna().index)set([date,:].dropna().index)set([date,:].dropna().index))x=([list(returns_3[date,sec_list]),list([date,sec_list])]).Ty=([date,sec_list])iflen(x)0andlen(y)0:linreg=LinearRegression(fit_intercept=True)model=(x,y)y_pred=(x)[date,sec_list]=y-y_pred
lambd=[]r_2=[]:sec_list=list(set(returns_3[date,:].dropna().index)set(forward_return_one_[date,:].dropna().index)set([date,:].dropna().index)set([date,:].dropna().index))iflen(sec_list)0:x=([list(returns_3[date,sec_list]),list([date,sec_list]),list([date,sec_list])]).Ty=(forward_return_one_[date,sec_list])linreg=LinearRegression(fit_intercept=True)model=(x,y)(_[2])r_2.app((x,y))
printu'IVR因子','p-value:',_1samp(lambd,0)[1],';','可决系数均值:',(r_2)
IVR因子p-value:4.2880711008e-10;可决系数均值:0.0411817522236
IVR因子系数的显著性检验通过,所以应该把IVR因子加入到因子库当中。
我们最终选择了三个因子,分别是3个月反转收益因子,非流动性因子,还有特异度因子,我们看看在筛选过程中横截面回顾可决系数的变化。
r_2_mean=(data=r_2_mean,index=['return_1_m','illiquidity','ivr'])fig=(figsize=(8,6))ax=_subplot(111)ax=r_2_(kind='bar',ax=ax,leg=False)s=_title('$R^{2}#39;)
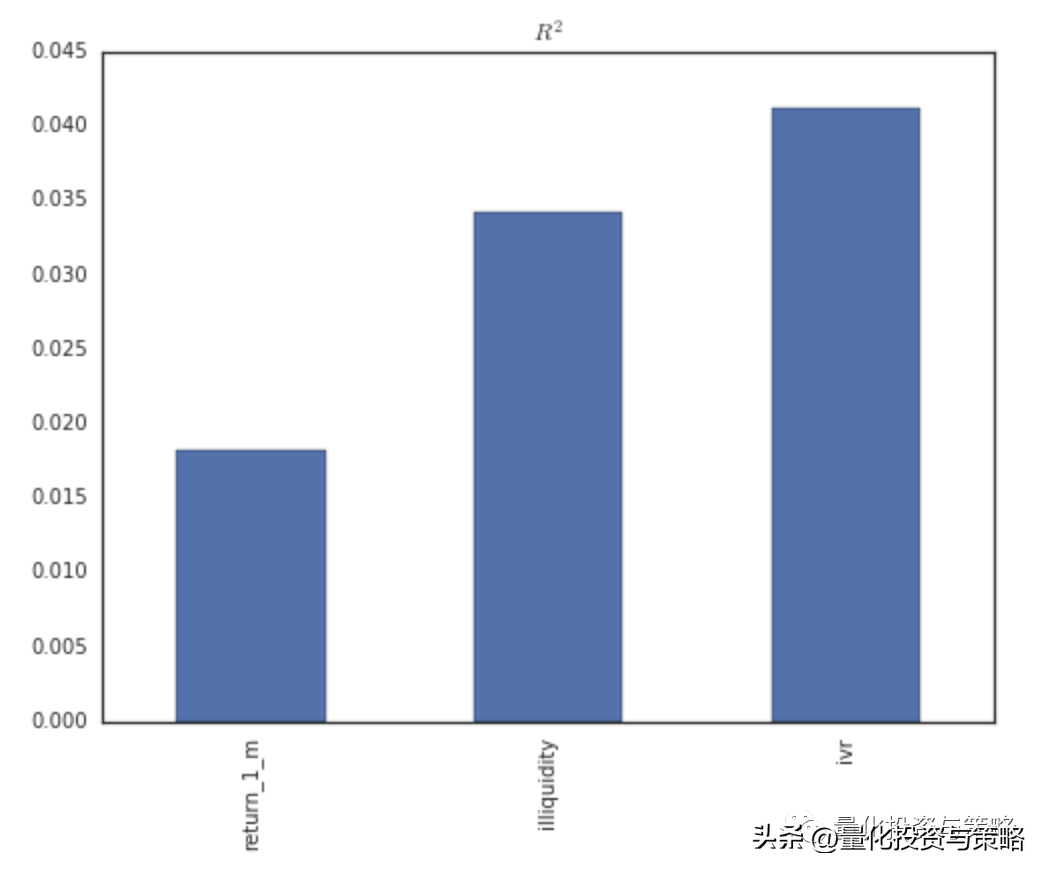
虽然因子数量比较少,但是从上图也可以看出,再添加第二个因子后,R2有了一定程度的提高,但添加了特异度因子后,提高的幅度有所减小,说明新因子给因子库增加的信息有限。
版权声明:本站所有作品(图文、音视频)均由用户自行上传分享,仅供网友学习交流,不声明或保证其内容的正确性,如发现本站有涉嫌抄袭侵权/违法违规的内容。请举报,一经查实,本站将立刻删除。